
This was originally part of a final project for Search Informatics, but my fascination with network visualization cropped up here and I thought it was worth sharing. This is a condensed version of the full article, and naturally the code is available on GitHub.
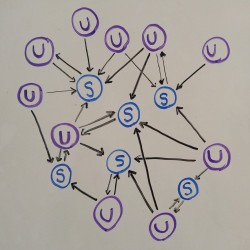
In “fanfic world” there are users and stories. Users can review fanfics and write fanfics. Each of these are shown with a directed edge: stories point to their authors, authors point to their stories, and readers point to stories they reviewed. The challenge is to decide which fanfics are relevant based on keywords, and which fanfics are most popular based on PageRank.
A single-edge shows a review, a double-edge shows authorship, and a triple-edge means that the user wrote and reviewed their own story.
Some stories receive only a small amount of attention.
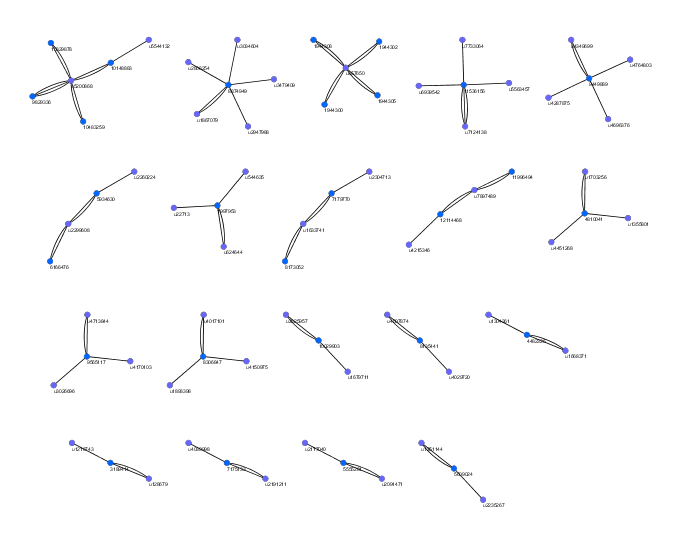
As we move toward the center, we notice that the vast majority of stories and users are highly-connected.

At the time this data was pulled, there were 6520 stories written in 15 languages over the course of twelve years. Totalling to a little over 30,000 chapters and millions of words.

Code Highlights
The question comes up occasionally for how to pull story IDs from FanFiction.Net. This is straightforward with a short bash script:
1
2
3
4
5
6
7
8
9
10
11
#!/bin/bash
# On a particular date, there were 285 pages of stories.
BASE="https://www.fanfiction.net/cartoon/Code-Lyoko/?&srt=1&r=10&p="
for i in {1..285}; do
URL=$BASE$i
echo "$URL"
PAGE="`wget --no-check-certificate -q -O - $URL`"
echo "$PAGE" | grep "class=stitle" | cut -c117-137 | cut -d'/' -f 3 >> sids.txt
sleep 6
done
This will create a URL by appending the number to the base (notice the p= at the end), downloading the page, finding the “class=stitle”, cutting the sids out and appending them to the end of a file called “sids.txt,” then waiting a few seconds in compliance with the terms of service.