Overview
SRLBoost: ⚡ Fast implementations of boosted relational dependency networks and Markov logic networks.
- Source Code: https://github.com/srlearn/SRLBoost
Getting Started
SRLBoost can be built as a maven package. For example, on Windows:
git clone https://github.com/srlearn/SRLBoost.git
cd .\SRLBoost\
mvn package
Then learning should feel familiar if you’re familiar with other
distributions like BoostSRL. After switching out X.Y.Z
with the latest version:
java -jar .\target\srlboost-X.Y.Z-jar-with-dependencies.jar -l -train .\data\Toy-Cancer\train\ -target cancer
Full notes are available with the repository: https://github.com/srlearn/SRLBoost#getting-started
Motivation
- I was one of the main people behind releasing “BoostSRL,” but wanted to go in a different direction with the software.
- At one point there was discussion around developing a “BoostSRL-Lite” implementation. But this didn’t really go anywhere (and as you’ll see in the benchmark, it wasn’t especially lite).
SRLBoost aims to be a small and fast core—not to implement every possible feature.
Benchmarks
Size Comparison
“BoostSRL-Lite” cut around 6,000 lines of Java out of “BoostSRL.”
“SRLBoost” cut close to 50,000 lines of code.
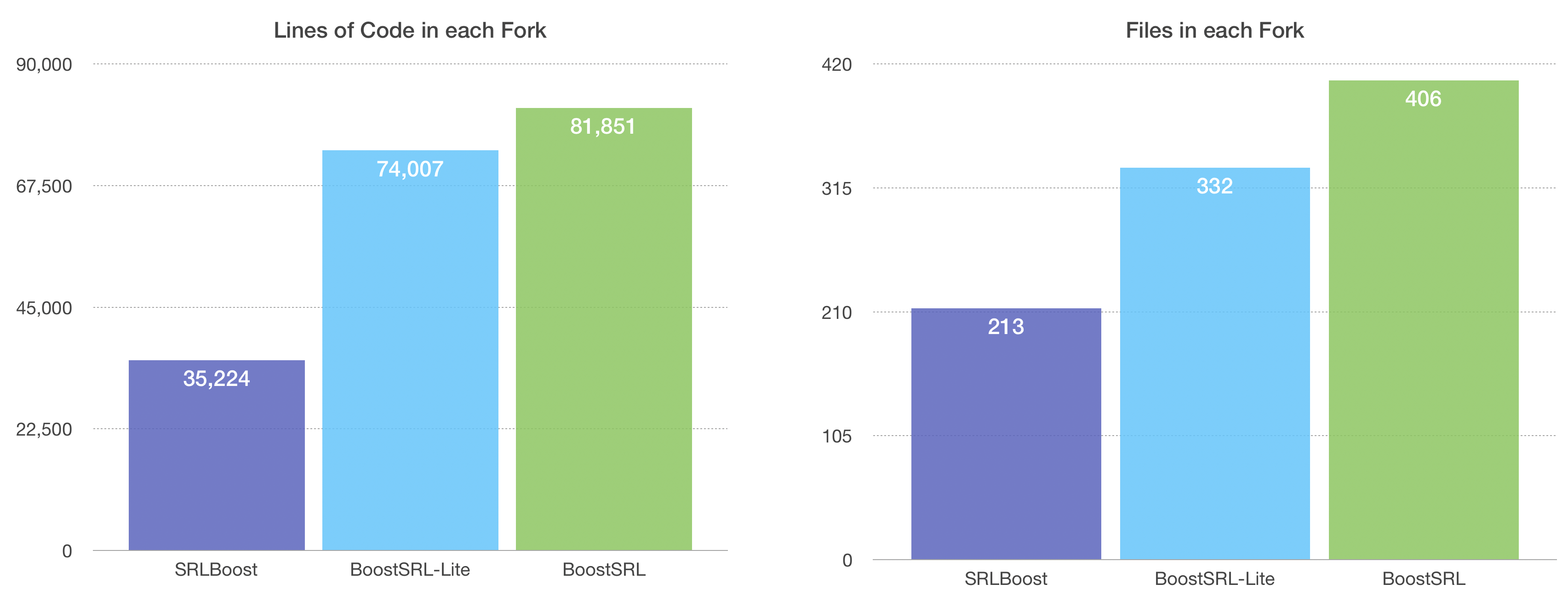
cb952a4, BoostSRL-Lite commit e198b76, and BoostSRLv1.1.1 at commit 4f0ad2b. Lines of code were measured with cloc-1.84, and Java files in each source directory were counted.Time Comparison
- “BoostSRL” and “BoostSRL-Lite” are nearly indistinguishable in terms of runtime
- “SRLBoost” is at least twice as fast
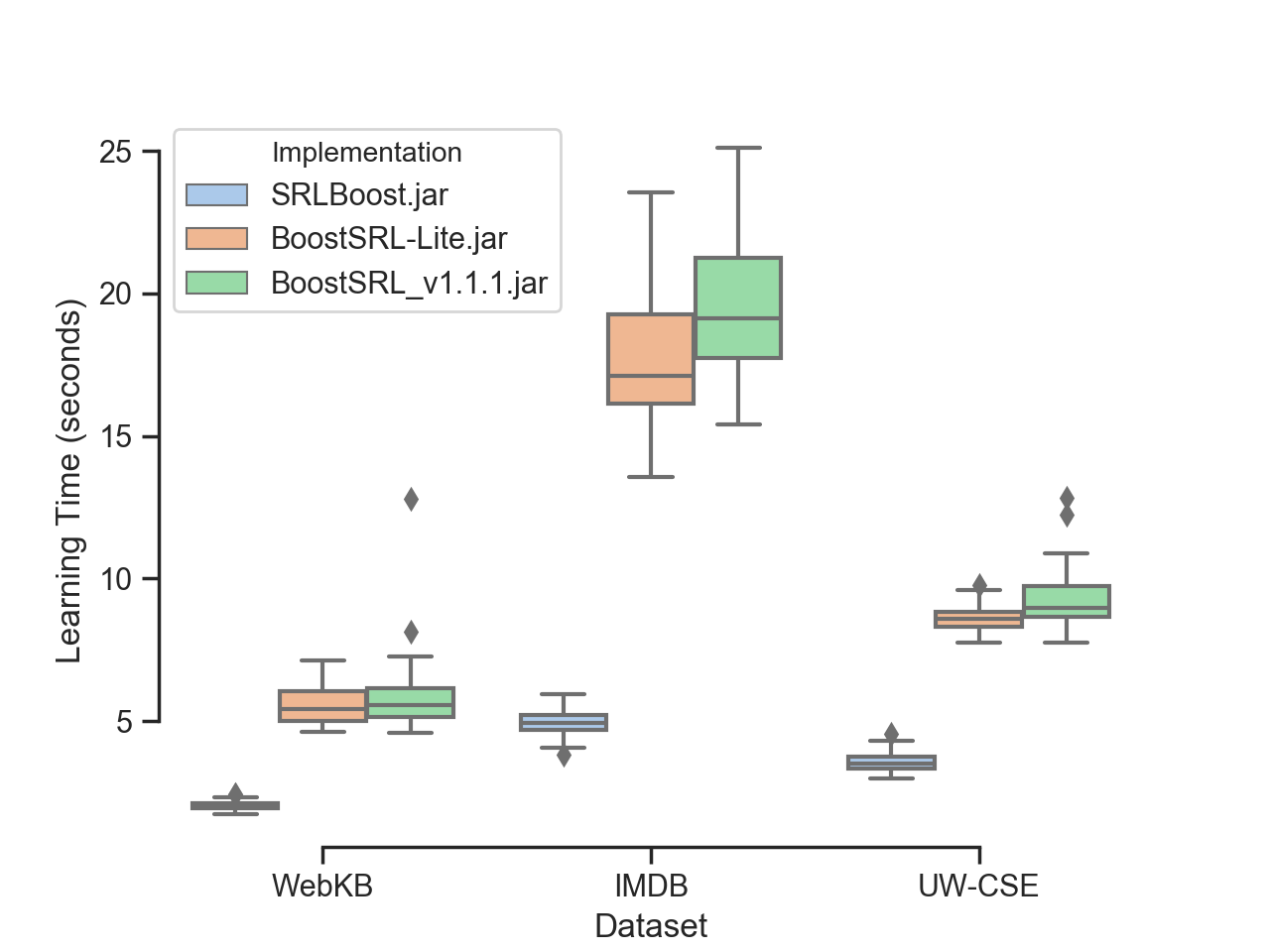
The following diagram compares the learning time (in seconds)
for the three implementations on three benchmark datasets.
On larger datasets like imdb, SRLBoost took an average of 5 seconds
while the other two implementations took close to 20 seconds:
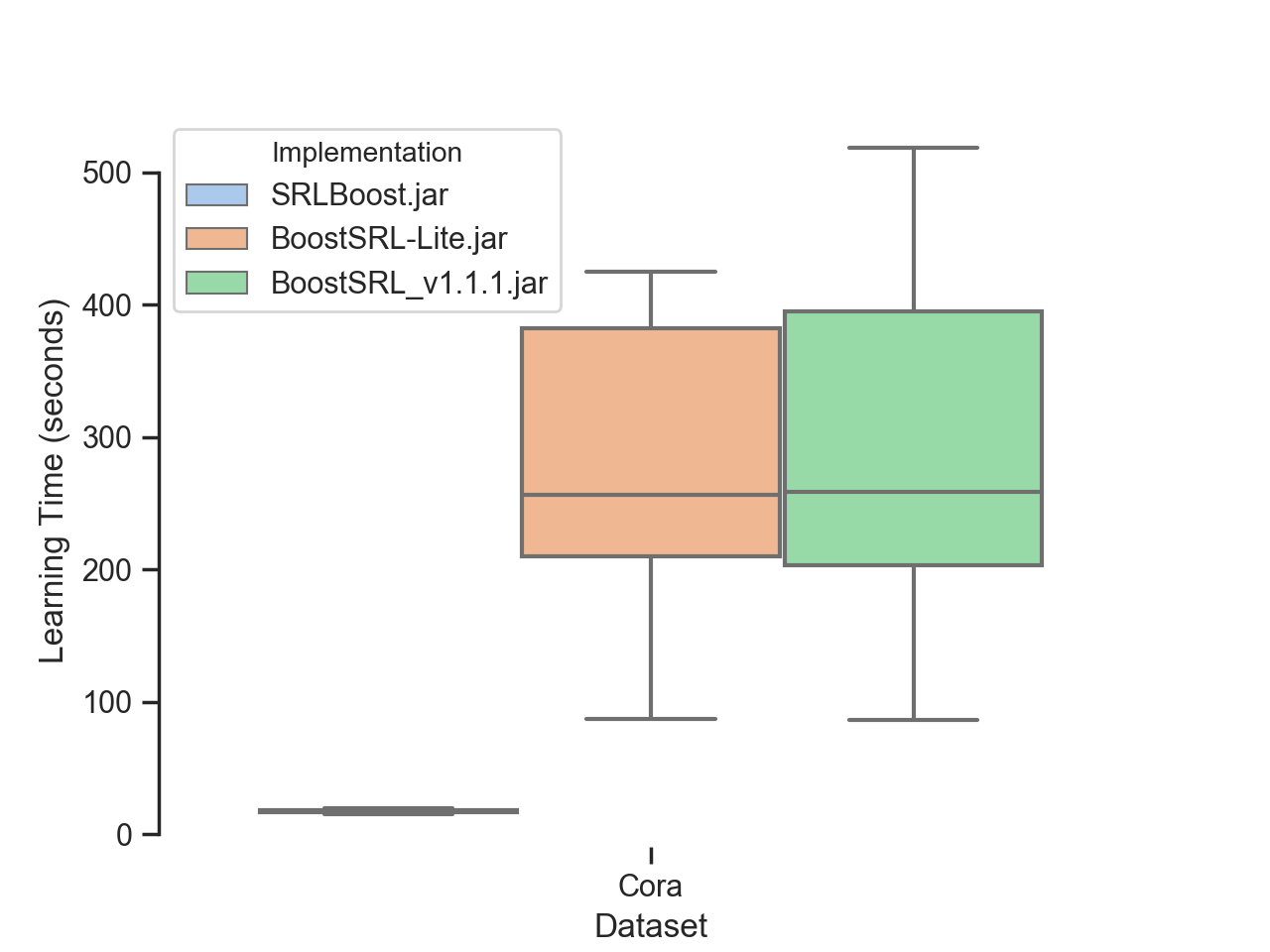
On large datasets with lots of relations (like cora), this difference is even
more pronounced. SRLBoost is so much faster that it’s difficult to
visualize the difference on a linear scale:
Are there any downsides?
Metrics are indistinguishable on the first three datasets.
But on the cora benchmark, being 15x faster also led to
differences in some key metrics. Specifically,
AUC-ROC decreased by 0.04 and AUC-PR decreased by 0.01.
BoostSRL-v1.1.1 appeared to have significantly worse F1 compared to the other two implementations, but it’s unclear why.1
| Implementation | cora mean AUC ROC | cora mean AUC PR | cora mean CLL | cora mean F1 |
|---|---|---|---|---|
| SRLBoost | 0.61 | 0.93 | -0.27 | 0.96 |
| BoostSRL-Lite | 0.65 | 0.94 | -0.29 | 0.96 |
| BoostSRLv1.1.1 | 0.65 | 0.94 | -0.29 | 0.78 |
Conclusion
I’m implementing this as the core for srlearn, so most of the user interfaces
for using SRLBoost are documented there.