Overview
nuMoM2b-preprocessing: Preprocessing scripts to create reproducible partitions of the nuMoM2b data set.
- Source Code: https://github.com/hayesall/nuMoM2b_preprocessing
Motivation
I was pretty involved in the Precision Health Initiative, nuMoM2b project, and follow-up Hoosier Moms Cohort study.
I immediately ran into a problem where there were tens of thousands of variables and it wasn’t obvious whether colleagues were using the same variables or the same preprocessing steps.
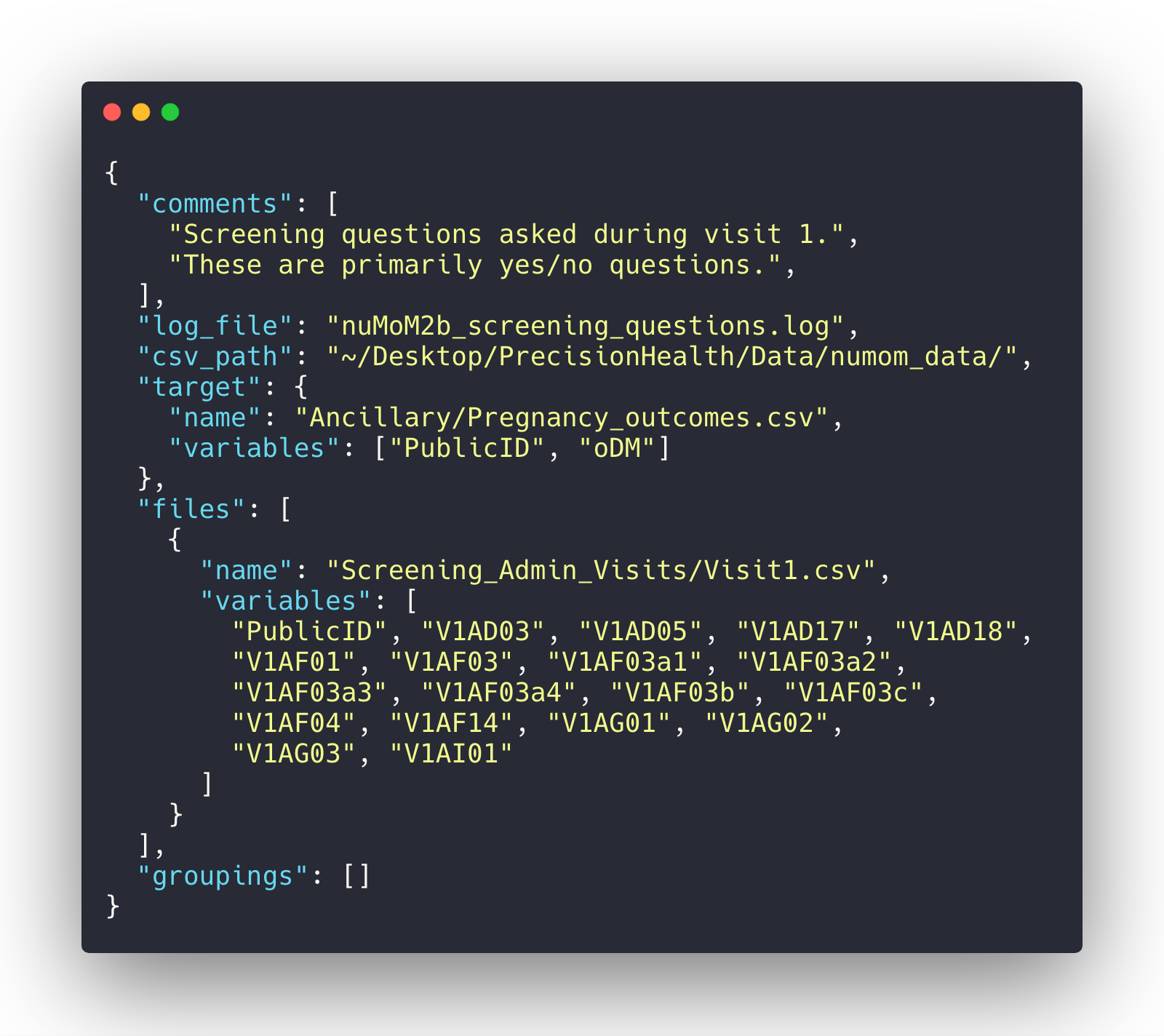
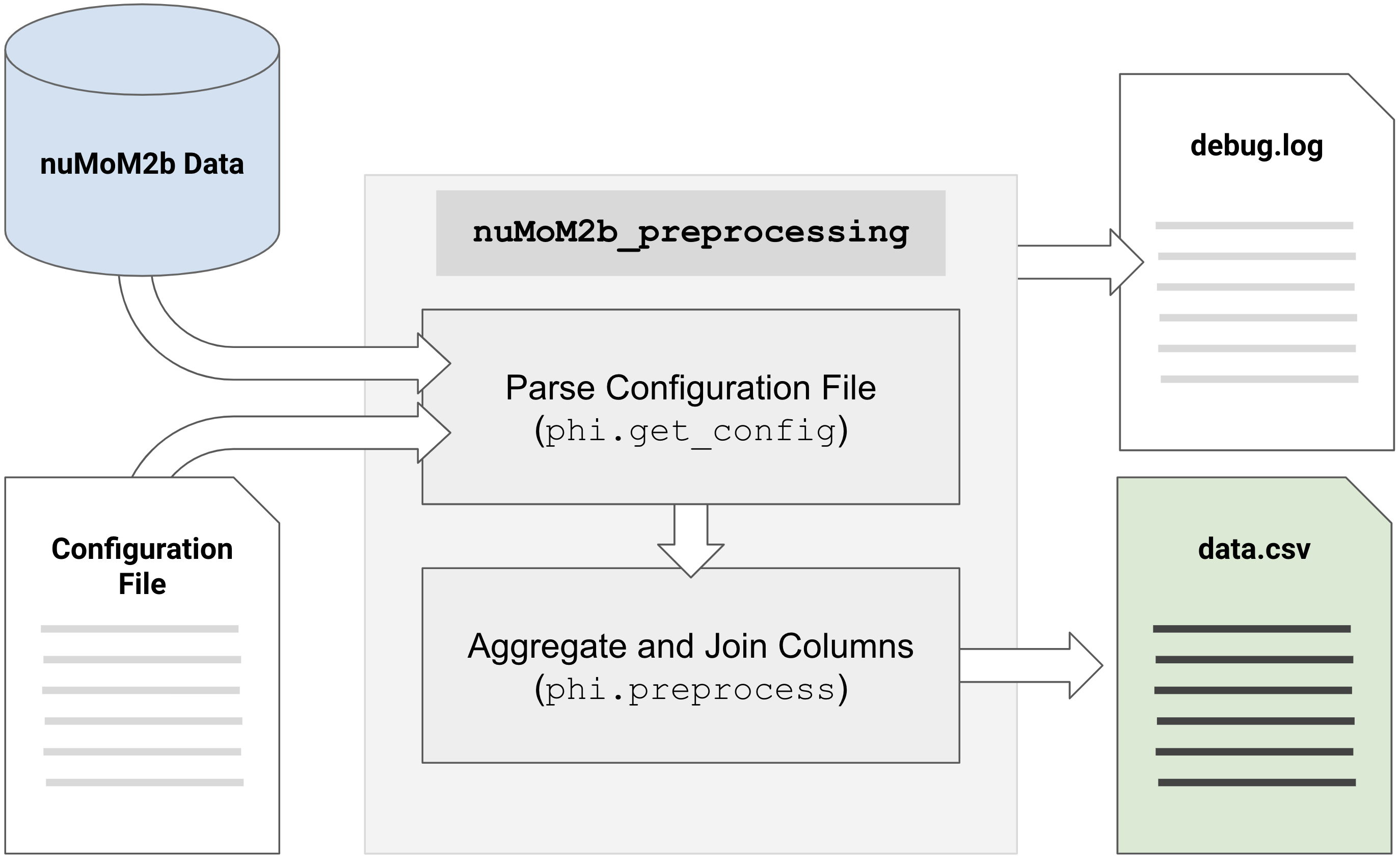
What I wanted was a simple domain-specific language (DSL) to describe where CSV files were stored, what variables I wanted out of them, and how to merge them into a single design matrix. It never evolved beyond the JSON representation, but I found this extremely helpful.